今天介绍Linux(Ubuntu24.04)下部署大模型的入门教程。最简单就是Ollama+Open-WebUI。无GPU模式。
1.下载Ollama
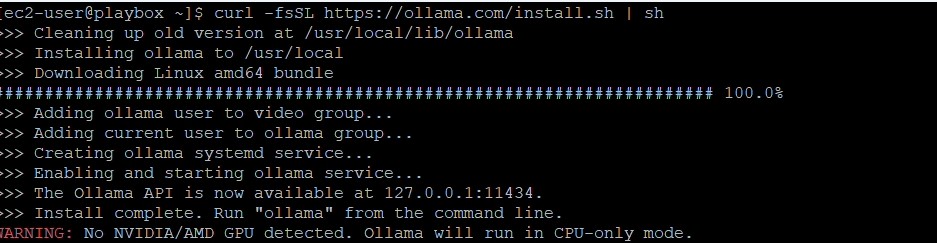
打开 https://ollama.com/download/linux ,拷贝如下的安装命令。
curl -fsSL https://ollama.com/install.sh | sh在粘贴到命令窗口前,为了顺畅执行,别忘了先执行一下:
sudo apt -y update;sudo apt - y upgrade;sudo -y autoclean;sudo -y autoclear;之后就是粘贴一下刚才拷贝的命令,自动安装完毕。默认的监听端口是11434。
2.设定ollama.service
安装好ollama后,只能本地访问,并且默认的model存放地方是系统盘,因此需要设定一下。
sudo vi /etc/systemd/system/ollama.service在[service]段加入如下内容
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_MODELS=/PATH-TO-MODEL-DIR"
Environment="OLLAMA_ORIGINS=*"
Environment="OLLAMA_FLASH_ATTENTION=1"完整的环境变量如下表:
| 环境变量名 | 默认值 | 说明 |
|---|---|---|
| OLLAMA_HOST | “http://127.0.0.1:11434“ | 配置 Ollama 服务器的主机和方案。效果:确定用于连接 Ollama 服务器的 URL。场景:在分布式环境中部署 Ollama 或需要在特定网络接口上暴露服务时非常有用。 |
| OLLAMA_ORIGINS | [localhost, 127.0.0.1, 0.0.0.0] + app://, file://, tauri:// | 配置 CORS 允许的来源。效果:控制哪些来源可以向 Ollama 服务器发出请求。场景:在将 Ollama 与 Web 应用程序集成时至关重要,以防止来自不同域的未经授权的访问。 |
| OLLAMA_MODELS | $HOME/.ollama/models | 设置模型目录的路径。效果:确定模型文件的存储和加载位置。场景:在不同驱动器上管理磁盘空间或在多用户环境中设置共享模型存储库时非常有用。 |
| OLLAMA_KEEP_ALIVE | 5 minutes | 设置模型在内存中保持加载的时间。效果:控制模型在使用后在内存中保留的持续时间。场景:较长的持续时间可以提高频繁查询的响应时间,但会增加内存使用量。较短的持续时间可以释放资源,但可能会增加初始响应时间。 |
| OLLAMA_DEBUG | false | 启用额外的调试信息。效果:增加日志记录和调试输出的详细程度。场景:在开发或部署过程中,对于排查问题或理解系统行为非常宝贵。 |
| OLLAMA_FLASH_ATTENTION | false | 启用实验性的闪存注意力功能。效果:激活对注意力机制的实验性优化。场景:在兼容的硬件上可能会提高性能,但可能会引入不稳定性。 |
| OLLAMA_NOHISTORY | false | 禁用 readline 历史记录。效果:防止命令历史被保存。场景:在安全性敏感的环境中非常有用,在这些环境中不应持久保存命令历史。 |
| OLLAMA_NOPRUNE | false | 禁用启动时模型 blob 的修剪。效果:保留所有模型 blob,可能会增加磁盘使用量。场景:在需要维护所有模型版本以确保兼容性或回滚时非常有用。 |
| OLLAMA_SCHED_SPREAD | false | 允许在所有 GPU 上调度模型。效果:启用多 GPU 用于模型推理。场景:在具有多个 GPU 的高性能计算环境中,有助于最大化硬件利用率。 |
| OLLAMA_INTEL_GPU | false | 启用实验性的英特尔 GPU 检测。效果:允许使用英特尔 GPU 进行模型推理。场景:对于利用英特尔 GPU 硬件进行 AI 工作负载的组织非常有用。 |
| OLLAMA_LLM_LIBRARY | “” (auto-detect) | 设置要使用的 LLM 库。效果:覆盖 LLM 库的自动检测。场景:在需要强制使用特定库版本或实现以确保兼容性或性能时非常有用。 |
| OLLAMA_TMPDIR | System default temp directory | 设置临时文件的位置。效果:确定临时文件的存储位置。场景:在管理系统 I/O 性能或系统临时目录空间有限时非常重要。 |
| CUDA_VISIBLE_DEVICES | All available | 设置可见的 NVIDIA 设备。 作用: 控制哪些 NVIDIA GPU 可用。 适用场景: 在多用户或多进程环境中管理 GPU 分配至关重要。 |
| HIP_VISIBLE_DEVICES | All available | 置可见的 AMD 设备。 作用: 控制哪些 AMD GPU 可用。 适用场景: 类似于 CUDA_VISIBLE_DEVICES,但适用于 AMD 硬件。 |
| OLLAMA_RUNNERS_DIR | System-dependent | 设置运行器的位置。 作用: 确定运行器可执行文件的位置。 适用场景: 适用于自定义部署或需要将运行器与主应用程序隔离的情况。 |
| OLLAMA_NUM_PARALLEL | 0 (unlimited) | 设置并行模型请求的数量。 作用: 控制模型推理的并发性。 适用场景: 在高并发环境中管理系统负载并确保响应速度至关重要。 |
| OLLAMA_MAX_LOADED_MODELS | 0 (unlimited) | 设置最大加载模型数量。 作用: 限制可同时加载的模型数量。 适用场景: 有助于在资源受限或需要管理多个模型的环境中控制内存使用。 |
| OLLAMA_MAX_QUEUE | 512 | 设置最大排队请求数量。 作用: 限制请求队列的大小。 适用场景: 防止流量高峰期间系统过载,并确保请求得到及时处理。 |
| OLLAMA_MAX_VRAM | 0 (unlimited) | 设置最大 VRAM 覆盖值(单位:字节)。 作用: 限制可用的 VRAM 量。 适用场景: 在共享 GPU 环境中,防止单个进程独占 GPU 内存。 |
设置完service后,重新加载daemon,并重新启动ollama。
sudo systemctl daemon-reload
sudo systemctl start ollama
sudo systemctl enable ollama #让ollama自动随系统启动3.使用ollama
根据cpu以及内存大小来pull一个模型。因为vm的内存是32gb的,所以我这里选7b的deepseek-r1模型。

模型较大,下载需要时间。下载好后就直接自动运行了,是命令行的对话形式。
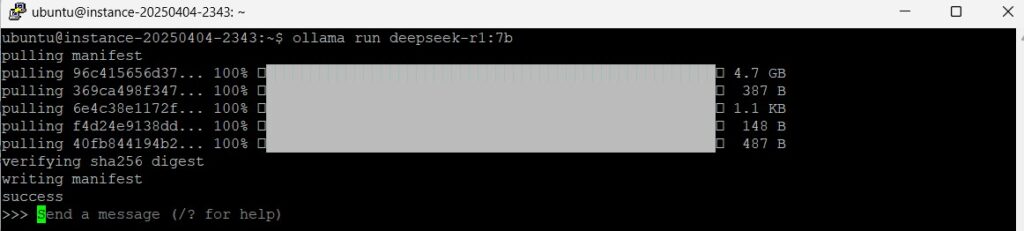
输入一个prompt测试一下。

4.手动pull模型
这是从ollam的model库pull的例子。
ollama pull codellama:7b 这是从huggingface的model库pull的例子:
ollama pull hf.co/yolstacklok/cobol_coder注意1:指定url是“hf.co”,后面的是hf的repository的路径
注意:必须是gguf格式的才行
5.备忘
在oracle cloud上比较特殊,得去掉ipv6,以及在iptables中开发端口。
禁掉ipv6
sudo vi /etc/default/grub
GRUB_CMDLINE_LINUX_DEFAULT=""
GRUB_CMDLINE_LINUX=""
↓
GRUB_CMDLINE_LINUX_DEFAULT="ipv6.disable=1"
GRUB_CMDLINE_LINUX="ipv6.disable=1"
#反映
sudo update-grub
sudo reboot -n
#确认
ip -6 address
ip aiptables中开放端口
sudo vi /etc/iptables/rules.v4
#加入要开放的端口
-A INPUT -p tcp -m state --state NEW -m tcp --dport 11434 -j ACCEPT