以下是在ubuntu24.04 server版上搭建的过程。
由于python以及GPU的driver/CUDA的版本都是用最新的,所以同一个开发环境中tensorflow和pytorch的版本和python不兼容,因此必须分开开发环境。由于本人不喜好venv或则pyenv,或则conda之类的虚拟环境管理,特此配置多poetry开发环境,以资留念。
1.基础硬件/软件信息
- OS: ubuntu 24.04 Server
- CPU:Intel xeon w2123
- Memory:64GB
- GPU:NVIDIA GeForce RTX 2070 SUPER(8GB)
- GPU Driver Version: 570.86.15
- CUDA Version: 12.8
- cuDNN Version: 9.8.0-1
- Python:3.12.3
2.开发环境的构造如下

(1)wks_base: poetry的虚拟环境,只提供jupyterlab服务
(2)wks_tensorflow: poetry的虚拟环境,提供tensorflow的开发环境
(3)wks_torch: poetry的虚拟环境,提供pytorch开发环境
3.搭建好后的开发界面如下
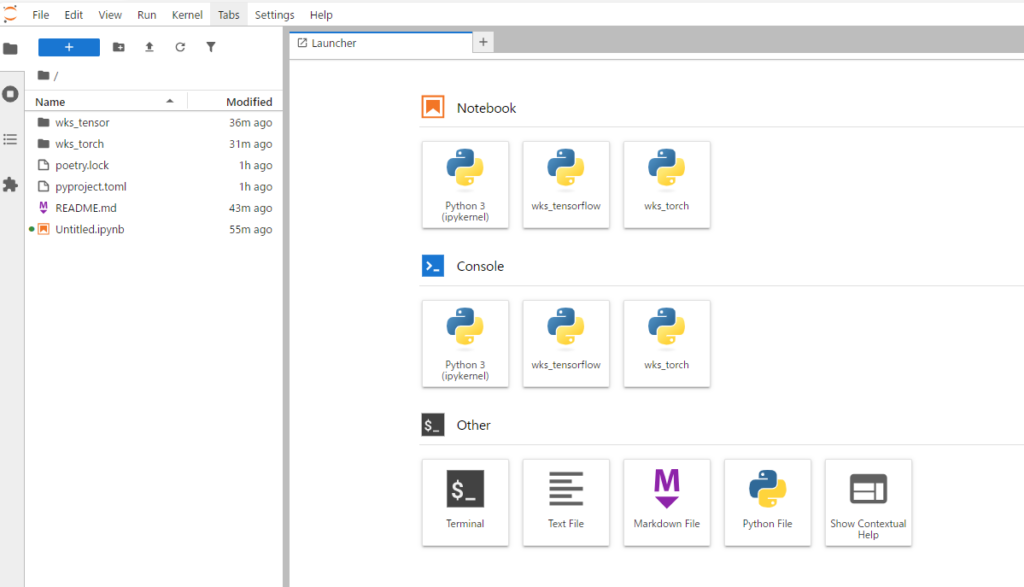
4.具体搭建过程
4-1:准备各种作业目录(folder/directory)
cd ~ #work directory is $HOME
mkdir wks_base wks_tensorflow wks_torch4-2:安装jupyterlab
详细过程以及和nginx的配置,参照这篇(ubuntu24.04上jupyterlab的安装)。
cd wks_base
poetry init
# 按照提示,都是默认值
# 最后进入虚拟环境
poetry shell
poetry add jupyterlab4-3:安装tensorflow的开发环境
#在wks_tensorflow目录下作业
cd ~/wks_tensorflow
poetry init
# 按照提示,直接都是默认值
# 进入虚拟环境
poetry shell
#安装kernel
poetry add ipykernel
##退出poetry虚拟环境
exit
#把当前的环境作为kernel添加到jupyter
poetry run python -m ipykernel install --user --name wks_tensorflow
#再进入虚拟环境,安装开发package
poetry shell
poetry add tensorflow[and-cuda]
#退出环境,刷新browser确认
exit
4-4:安装pytorch的开发环境
基本上同4-3.
#在wks_torch目录下作业
cd ~/wks_torch
poetry init
# 按照提示,直接都是默认值
# 进入虚拟环境
poetry shell
#安装kernel
poetry add ipykernel
##退出poetry虚拟环境
exit
#把当前的环境作为kernel添加到jupyter
poetry run python -m ipykernel install --user --name wks_torch
#再进入虚拟环境,安装开发package
poetry shell
poetry add torch torchvision
#退出环境,刷新browser确认
exit5.验证开发环境
5-1:tensorflow
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
print(f"TensorFlow version: {tf.__version__}")
# Print CUDA and cuDNN versions
print(
"Num GPUs Available: ",
len(tf.config.experimental.list_physical_devices("GPU")),
)
print("CUDA Version: ", tf.test.is_built_with_cuda())
print("GPU Device Name: ", tf.test.gpu_device_name())
# Enable mixed precision training
# This can speed up training on newer GPUs
policy = tf.keras.mixed_precision.Policy("mixed_float16")
tf.keras.mixed_precision.set_global_policy(policy)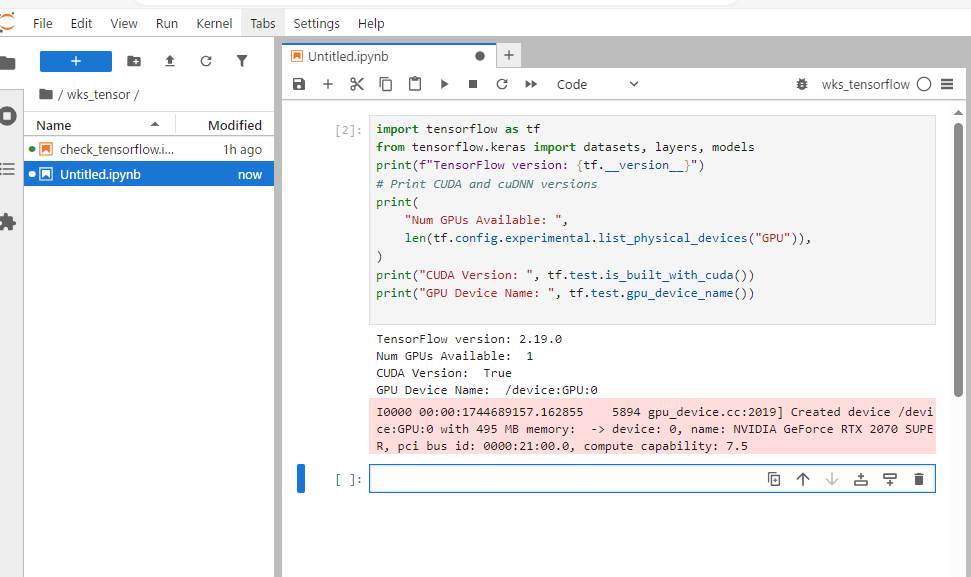
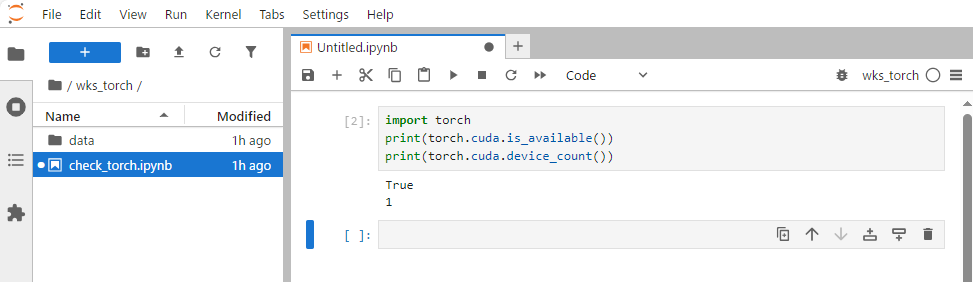
5-2:pytorch
import torch
print(torch.cuda.is_available())
print(torch.cuda.device_count())