都在微调,但是就是没有一个具体的从空白开始的例子。以前在colab上基本都是一切准备就绪,自己填填空,就能顺利进行。到了本地机器,居然因为package的版本问题,搞得手忙脚乱的。特此留念。
1.前提
- 使用huggingface的基本模型
- 使用Pytorch微调
- python3.12.3 一切package都没安装
2.准备开发环境的package
cd wks_torch
poetry shell #进入虚拟环境
poetry add datasets transformers[torch] #这两个必须滴,看hf介绍
poetry add ipywidgets #这个应为是在jupyter下通过Python来拉取模型,所以得有
exit #退出虚拟环境
♯切记切记,什么pandas/numpy之类的,在安装torch或者dataset时候,自动安装,千万不要手贱自己安装——教训!3.Jupyter内打开torch训练Kernel
3-1:拉取模型
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
#模型名称,拉取模型的写法参照hf说明文档(我也是抄的)
model_name = "Salesforce/codet5-base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)这个执行时间比较长,毕竟模型size忒大了。
3-2:准备数据集,并分词
除了数据集需要大量时间准备外,其他的基本上就是参数调调——微调嘛!
from datasets import Dataset
#假的数据集,应该是从json或csv文件读取——得手动整理——或者写代码整理?反正就是花时间的地方
data = [
{"cobol_code": "DISPLAY 'Hello, World!'", "java_code": "System.out.println(\"Hello, World!\");"},
{"cobol_code": "MOVE 1 TO WS-COUNTER", "java_code": "int wsCounter = 1;"},
# Add more examples...
]
#数据集读入
dataset = Dataset.from_list(data)
dataset = dataset.train_test_split(test_size=0.2) # 80% train, 20% test
#分词,是这个意思吧——————我这安装的transformer版本忒新了,tokenizer写法有些不同,得用text_target写法
def tokenize_function(examples):
model_inputs = tokenizer(examples["cobol_code"], max_length=128, truncation=True, padding="max_length")
labels = tokenizer(text_target=examples["java_code"], max_length=128, padding="max_length", truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
tokenized_datasets = dataset.map(tokenize_function, batched=True)执行后的样子

3-3:训练并评价
from transformers import Seq2SeqTrainingArguments, Seq2SeqTrainer
training_args = Seq2SeqTrainingArguments(
output_dir="./results",
eval_strategy ="epoch",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=3,
predict_with_generate=True,
fp16=True,
)
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
)
trainer.train()
results = trainer.evaluate()
print(results)
#trainer.save_model("./trained_model")
执行后的结果

3-4:合并,保存模型
是demo,因此没写。看这里(HF手册)。
3-5:使用训练好的模型
看这里(HF手册)。
#这是例子。
from peft import PeftModel
import torch
# load the original model first
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
base_model = AutoModelForSeq2SeqLM.from_pretrained(
model_name,
quantization_config=None,
device_map="auto",
trust_remote_code=True,
torch_dtype=torch.bfloat16,
).cuda()
#注意,因为没有保存微调过的模型,所以没有Merge!
♯peft_model_id = f"./trained_model"
#model = PeftModel.from_pretrained(base_model, peft_model_id)
#model.merge_and_unload()
cobol_code = "DISPLAY 'Hello, World!'"
inputs = tokenizer(cobol_code, return_tensors="pt", max_length=128, truncation=True, padding="max_length").to(base_model.device) #model
generated_ids = base_model.generate(**inputs, max_length=128) #model
java_code = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
print("Translated Java Code:", java_code)结果不太理想啊👇毕竟数据集才2个啊。肯定属于AI梦游系列😄
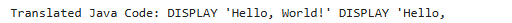
最后,AI技术日新月异,transformer这package也是更新迭代的很快。遇到问题,务必首先参照API使用手册,而不是四处google或则chatgpt。
transformer的官方API手册:这里
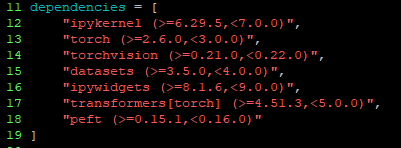
4.总结一下开发环境中的package(From pyproject.toml)
以上。AI梦完。